准备工作
首先,先建一张测试表。
CREATE TABLE `sys_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id',
`username` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名',
`password` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '密码',
`salt` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '盐',
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
KEY `idx_uname_pwd` (`username`,`password`)
) ENGINE=InnoDB AUTO_INCREMENT=2769446 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='系统表'
利用脚本往里面插入100W的数据,可以参考我这篇文章。
mysql> select count(*) from sys_user;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.10 sec)
普通索引
我先不建索引进行查询。
mysql> select * from sys_user where username = '0tez09Bo';
+---------+----------+------------------+------------------+---------------------+---------------------+
| id | username | password | salt | gmt_create | gmt_modified |
+---------+----------+------------------+------------------+---------------------+---------------------+
| 1769448 | 0tez09Bo | 09BnXshPbgA18vX4 | moLsOAhxEujXGpOH | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769451 | 0tez09Bo | 5u1s4QOnh7CAUDfc | 6KgUB6AtsFQ1oNDB | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769454 | 0tez09Bo | OuTM3OJ3Ugo3S7Nq | BzRrvZjr75U8LfMZ | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769456 | 0tez09Bo | jEaK4WjCXLQITaZj | q3OIZE6rI454WixC | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769458 | 0tez09Bo | YvvQvSGCRlWuwY8C | tpqMqEOW7DD8zjFe | 2020-01-01 14:44:32 | 2020-01-01 14:44:32 |
| 1769461 | 0tez09Bo | oYvtFMI30Gg5w80q | Yr776WgmQYcTJOGP | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769474 | 0tez09Bo | MCzTxUIHeSz0cOhM | Xfb4BFlyA9Mj27k8 | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769484 | 0tez09Bo | 8EJwgC9HS9Yd0g6y | kQ3ytyb7ROiUspyl | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769492 | 0tez09Bo | t3IcJRW022UflR7Q | IS4xjP2wn8oqMsMn | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769504 | 0tez09Bo | YEcUN2GaAjCZXGku | gHxstQFCWGpRWWJE | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
+---------+----------+------------------+------------------+---------------------+---------------------+
10 rows in set (0.25 sec)
我们可以看到,在不见索引的情况下,查询耗时为0.25s。
接下来,我们为sername添加索引,再次执行。
mysql> alter table sys_user add index `idx_username` (username);
mysql> select * from sys_user where username = '0tez09Bo';
+---------+----------+------------------+------------------+---------------------+---------------------+
| id | username | password | salt | gmt_create | gmt_modified |
+---------+----------+------------------+------------------+---------------------+---------------------+
| 1769448 | 0tez09Bo | 09BnXshPbgA18vX4 | moLsOAhxEujXGpOH | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769451 | 0tez09Bo | 5u1s4QOnh7CAUDfc | 6KgUB6AtsFQ1oNDB | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769454 | 0tez09Bo | OuTM3OJ3Ugo3S7Nq | BzRrvZjr75U8LfMZ | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769456 | 0tez09Bo | jEaK4WjCXLQITaZj | q3OIZE6rI454WixC | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769458 | 0tez09Bo | YvvQvSGCRlWuwY8C | tpqMqEOW7DD8zjFe | 2020-01-01 14:44:32 | 2020-01-01 14:44:32 |
| 1769461 | 0tez09Bo | oYvtFMI30Gg5w80q | Yr776WgmQYcTJOGP | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769474 | 0tez09Bo | MCzTxUIHeSz0cOhM | Xfb4BFlyA9Mj27k8 | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769484 | 0tez09Bo | 8EJwgC9HS9Yd0g6y | kQ3ytyb7ROiUspyl | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769492 | 0tez09Bo | t3IcJRW022UflR7Q | IS4xjP2wn8oqMsMn | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
| 1769504 | 0tez09Bo | YEcUN2GaAjCZXGku | gHxstQFCWGpRWWJE | 2020-01-01 14:44:32 | 2020-01-01 15:22:47 |
+---------+----------+------------------+------------------+---------------------+---------------------+
10 rows in set (0.00 sec)
我们可以看到,查询瞬间为毫秒级了。由此看见,索引对查询的性能提升是显而易见的。
但是一般业务中的查询都会同时用多个条件,此时单个索引的提升就不这么明显了,对于组合条件查询的我们一般会建联合索引。
联合索引
我们为user_name和password建立联合索引。
mysql> alter table sys_user add index `idx_uname_pwd` (username,password);
进行查询测试一下。
mysql> select * from sys_user where username = '0tez09Bo' and password = 'YvvQvSGCRlWuwY8C';
+---------+----------+------------------+------------------+---------------------+---------------------+
| id | username | password | salt | gmt_create | gmt_modified |
+---------+----------+------------------+------------------+---------------------+---------------------+
| 1769458 | 0tez09Bo | YvvQvSGCRlWuwY8C | tpqMqEOW7DD8zjFe | 2020-01-01 14:44:32 | 2020-01-01 14:44:32 |
+---------+----------+------------------+------------------+---------------------+---------------------+
1 row in set (0.00 sec)
效果很明显,但是当我们用password单个条件查询时,会发现又变的很慢。
mysql> select * from sys_user where password = 'YvvQvSGCRlWuwY8C';
+---------+----------+------------------+------------------+---------------------+---------------------+
| id | username | password | salt | gmt_create | gmt_modified |
+---------+----------+------------------+------------------+---------------------+---------------------+
| 1769447 | 1f2haNiY | YvvQvSGCRlWuwY8C | rDFjnPNomvgEhjxA | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769452 | WIEVvAht | YvvQvSGCRlWuwY8C | mpQMfHCQabdpdGBM | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769458 | 0tez09Bo | YvvQvSGCRlWuwY8C | tpqMqEOW7DD8zjFe | 2020-01-01 14:44:32 | 2020-01-01 14:44:32 |
| 1769581 | zZ7pzsrE | YvvQvSGCRlWuwY8C | 3UdelSdfqdGAJKmp | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769611 | qbsBsj14 | YvvQvSGCRlWuwY8C | LEPZkwuFLCEf6EKE | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769641 | zRofUFpU | YvvQvSGCRlWuwY8C | bqowgDbSHGaEzIIg | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769673 | icZaK1Kv | YvvQvSGCRlWuwY8C | EShAUElCUyPmaAfk | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769704 | y8QHMELH | YvvQvSGCRlWuwY8C | CLPGLCFimHg5tV4p | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769741 | al47gP97 | YvvQvSGCRlWuwY8C | 6hWICKLqDLJcDr9h | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
| 1769797 | Qa8ZnMCy | YvvQvSGCRlWuwY8C | TvIT7NuRHKtXc0g7 | 2020-01-01 14:44:32 | 2020-01-01 15:24:10 |
+---------+----------+------------------+------------------+---------------------+---------------------+
10 rows in set (0.25 sec)
这是怎么回事呢?我们明明给password建了索引,虽然是联合索引,但是怎么一点用都没有呢?
这个时候就需要神器explain分析一波了。
mysql> explain select * from sys_user where password = 'YvvQvSGCRlWuwY8C';
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | sys_user | NULL | ALL | NULL | NULL | NULL | NULL | 995244 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
首先,先介绍下,explain的主要返回参数。
- id
- 表示查询中执行select子句或操作表的顺序
- id相同,执行顺序从上往下
- id不同,id值越大,优先级越高,越先执行
- select_type
- 表示查询类型
- 种类
- simple(简单的select查询,查询中不包含子查询或者UNION)
- primary(查询中若包含任何复杂的子部分,最外层查询被标记)
- subquery(子查询)
- derived(临时表)
- union
- unionunion result
- table
- 输出的行所引用的表
- type
- 显示查询使用了何种类型
- 类型
- system(表中仅有一行)
- const(表示通过索引一次就找到)
- eq_ref(唯一性索引扫描)
- ref(非唯一性索引扫描)
- range(一个索引的范围搜索)
- index(遍历索引树)
- all(全表扫描)
查看explain重点是要看type这个字段,当type 为all或者index的时候,就需要优化我们的sql了。
我们看到,这条语句是进行全表扫描的,没有使用索引。这是为什么呢?
要解释这个问题,我们就要了解一下mysql的索引结构了。
一般来说,索引的数据结构可以为以下几种。
- 二叉树
- 特点
- 左右子树的高度差不超过1
- 缺点
- 多次IO
- 线性结构
- 特点
- B-Tree
- 特点
- 高度尽量低
- 每个索引块尽量存多的信息
- 规定快速查找规则
- 优点
- 减少IO读取
- 避免线性结构
- 特点
- B+Tree
- 特点
- 非叶子节点能存更多索引
- 数据都会保存在叶子节点中
- 叶子节点会有指向下个叶子节点的指针,方便范围统计
- 优点
- IO降低
- 查询更效率稳定
- 更利于数据库扫描
- 特点
- Hash结构
- 优点
- 查询更效率
- 缺点
- 不能范围查询
- 不能排序
- 不能利用部分索引
- hash相同时,不能避免表扫描
- 大量时,新性能低
- 优点
- BitMap
- 并发性能低
mysql采用的就是B+Tree,B+Tree有个很重要的原则,最左前缀匹配原则。
最左前缀匹配原则:mysql会按索引从左到右的顺序进行匹配,直到遇到范围查询(>、<、between、like)就停止匹配。
以复合索引(a,b)为例,如下图。
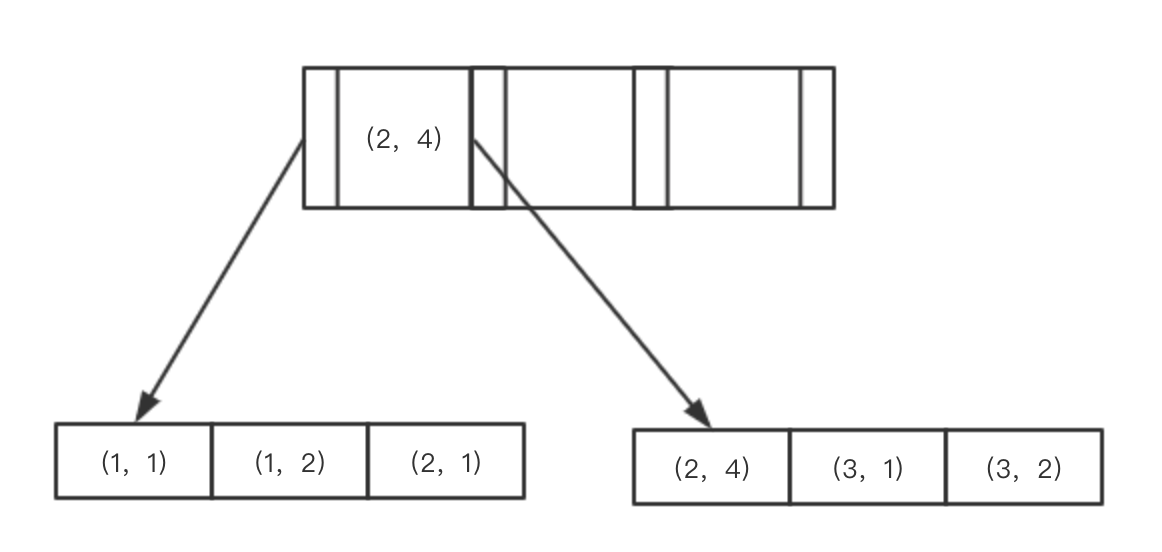
我们可以看到,a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。
所以password = 'YvvQvSGCRlWuwY8C'这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
a值相等的情况下,b值又是按顺序排列的,因此我们用sys_user where password = 'YvvQvSGCRlWuwY8C'查询时用到了索引,所以很快。
索引优化总结
- sql执行很慢时,可以用explain进行分析,看是否需要建索引。
- 当有了索引查询仍然慢时,我们就需分析一下查询条件,看是否满足最左前缀匹配原则。
业务查询优化
虽然索引能优化查询性能,但是给所有的字段都加索引又不现实,因为这样十分浪费空间且影响插入和更新。
因此,当表的数据量很大,且索引满足不了查询速度要求时,可以做以下几点优化。
- 分表。我们可以基于大表产生需要的利于查询的小表。比如,在全量表基础上抽取出,日表,周表、月表等,以满足不同时间段的查询。
- 将大的sql拆成小的sql执行。比如,你要查询仅半年的数据,一次性查询半年执行起来当然慢,我们可以按周来并行查询,然后将查询的结果汇总,这样执行就很快了。
- 如果你发现怎么优化都不能满足,数据量大的爆表。此时用mysql可能就不太合适了,建议使用ES等,搜索引擎,来满足更大更高效的查询。
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名,转载请标明出处
最后编辑时间为:
2020-01-01